Spark¶
Agenda¶
- Spark Internals
- Resilient Distributed Dataset (RDD)
- Operations on RDDs
What is Apache Spark¶
Apache Spark is an open-source distributed general-purpose cluster-computing framework. It was created by Matei Zaharia during his PhD.
Spark is written in Scala. Scala is written in Java. Spark runs on the Java Virtual Machine (JVM). A Java virtual machine (JVM) is a virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. Thats why one can run Spark using a Python programming API, it uses the py4j Python package to interact with the JVM. The Python programming API is called PySpark.
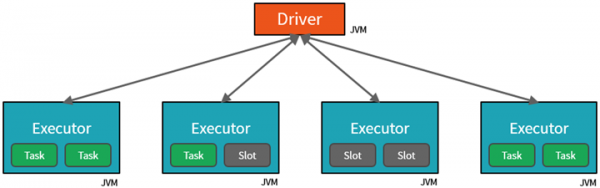
Cluster¶
A Spark cluster is made up of one Driver and many Executors / Worker nodes (they're all computers). The driver is the thing that runs whatever computation you run in a cell in Databricks.
# This runs on the driver.
1 + 1
2
Cluster¶
The Driver sends Tasks to the empty slots on the Executors when work has to be done. You can run as many tasks in parallel as the total number of cores in your cluster.
# This runs on the executors.
sc.parallelize([1, 1]).reduce(lambda x, y: x + y)
2
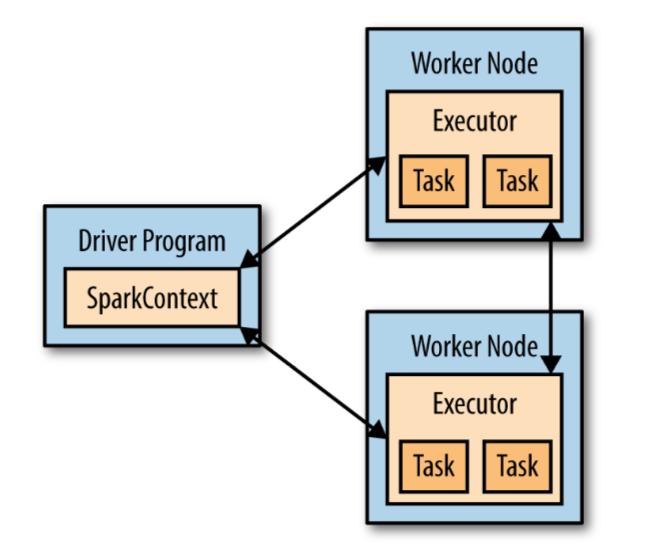
The SparkContext¶
Driver programs access Spark through a SparkContext object, which represents a connection to a computing cluster.
The SparkContext is initialized automatically in a Databricks notebook and assigned to the variable sc.
Resilient Distributed Datasets (RDD)¶
An RDD in Spark is an immutable distributed collection of objects. Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes. Under the hood, Spark automatically distributes the data contained in RDDs across your cluster and parallelizes the operations you perform on them.
Users create RDDs in two ways: by loading an external dataset, or by distributing a collection of objects from the driver.
parallelize(c, numSlices=None) Distribute a local Python collection to form an RDD.
Resilient Distributed Datasets (RDD)¶
# An RDD of ints.
sc.parallelize([1, 2, 3])
# An RDD of strings.
sc.parallelize(["pandas", "i like pandas"])
# An RDD of tuples.
sc.parallelize([(1), (2), (3)])
# An RDD of linear regression models.
from sklearn.linear_model import LinearRegression
sc.parallelize([LinearRegression() for _ in range(10)])
ParallelCollectionRDD[5] at readRDDFromFile at PythonRDD.scala:287
Example: Operations
used on an RDD
The RDD methods I've most commonly used are collect(), map(), flatMap(), filter() and count().
collect()Return a list that contains all of the elements in this RDD. Note This method should only be used if the resulting array is expected to be small, as all the data is loaded into the driver’s memory.take(num)does similar thing as.collect()but only collectsnumelements to the driver.map(f, preservesPartitioning=False)Return a new RDD by applying a function to each element of this RDD.flatMap(f, preservesPartitioning=False)Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results.flatMap()can take a generator which can be super useful.filter(f)Return a new RDD containing only the elements that satisfy a predicate.count()Return the number of elements in this RDD
collect()¶
Returns a list that contains all of the elements in this RDD. Note This method should only be used if the resulting array is expected to be small, as all the data is loaded into the driver’s memory.
rdd = sc.parallelize([i for i in range(10)])
rdd.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
map(f, preservesPartitioning=False)¶
Returns a new RDD by applying a function to each element of this RDD.
rdd = sc.parallelize([i for i in range(10)])
rdd.map(lambda x: x ** 2).collect()
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
flatMap(f, preservesPartitioning=False)¶
Returns a new RDD by first applying a function to all elements of this RDD, and then flattening the results. flatMap() can take a generator which can be super useful.
rdd = sc.parallelize([i for i in range(10)])
rdd.flatMap(lambda x: [x ** 2, x ** 3]).collect()
[0, 0, 1, 1, 4, 8, 9, 27, 16, 64, 25, 125, 36, 216, 49, 343, 64, 512, 81, 729]
flatMap(f, preservesPartitioning=False)¶
flatMap() works with a generator as well.
def generate_polynomial(x, degrees=2):
for d in range(degrees):
yield x ** d
rdd = sc.parallelize(range(10))
rdd.flatMap(generate_polynomial).collect()
[1, 0, 1, 1, 1, 2, 1, 3, 1, 4, 1, 5, 1, 6, 1, 7, 1, 8, 1, 9]
filter(f)¶
Return a new RDD containing only the elements that satisfy a predicate.
rdd = sc.parallelize([i for i in range(10)]).filter(lambda x: x > 5)
rdd.collect()
[6, 7, 8, 9]
take(num)¶
Does similar thing but only collects num elements to the driver.
sc.parallelize([i for i in range(10)]).take(3)
[0, 1, 2]
count()¶
Returns the number of elements in this RDD
sc.parallelize([i for i in range(10)]).count()
10
Transformations and Actions¶
RDDs offer two types of operations: transformations and actions.
Transformations construct a new RDD from a previous one. Actions on the other hand, compute a result based on an RDD, and either return it to the driver program or save it to an external storage system.
Transformations and actions are different because of the way Spark computes RDDs. Although you can define new RDDs any time, Spark computes them only in a lazy fashion—that is, the first time they are used in an action.
In above examples the map(), flatMap and filter() are transformations. collect(), take() and count() are actions.
Transformations and Actions¶
Transformations contribute to a query plan, but nothing is executed until an action is called.
Transformations, like map(), flatMap and filter() create a new RDD from an existing one, resulting in another immutable RDD. All transformations are lazy evaluated. That is, they are not executed until an action is invoked or performed.
Actions like count(), take(), collect() will result in a computation
rdd = sc.parallelize(range(10)).map(lambda x: x**2) # No computation.
rdd.count() # Computation.
10
Partitions¶
Actual physical data is distributed across storage as partitions residing in either HDFS or cloud storage. While the data is distributed as partitions across the physical cluster, Spark treats each partition as a high-level logical data abstraction—as a DataFrame in memory. Though this is not always possible, each Spark executor is preferably allocated a task that requires it to read the partition closest to it in the network, observing data locality.
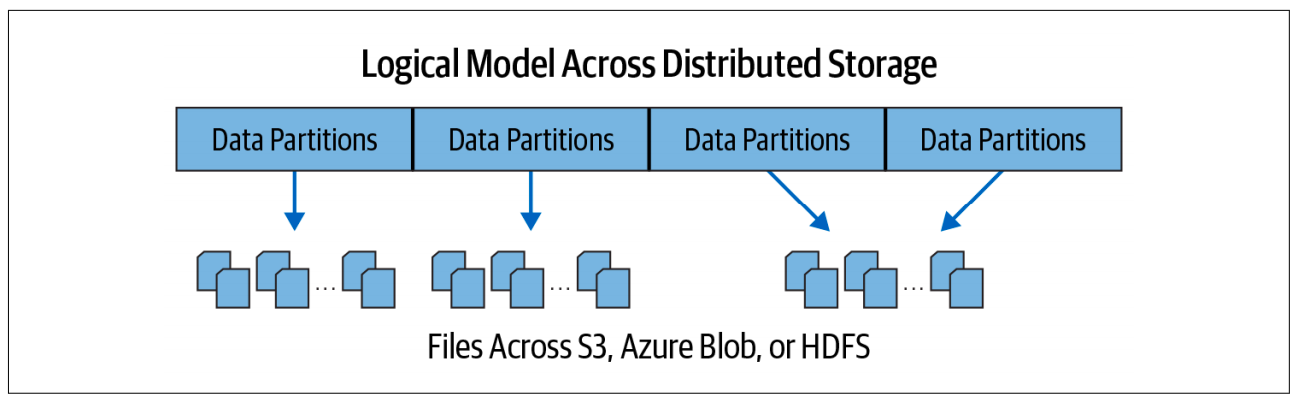
Partitions¶
Partitioning allows for efficient parallelism. A distributed scheme of breaking up data into chunks or partitions allows Spark executors to process only data that is close to them, minimizing network bandwidth. That is, each executor’s core is assigned its own data partition to work on.
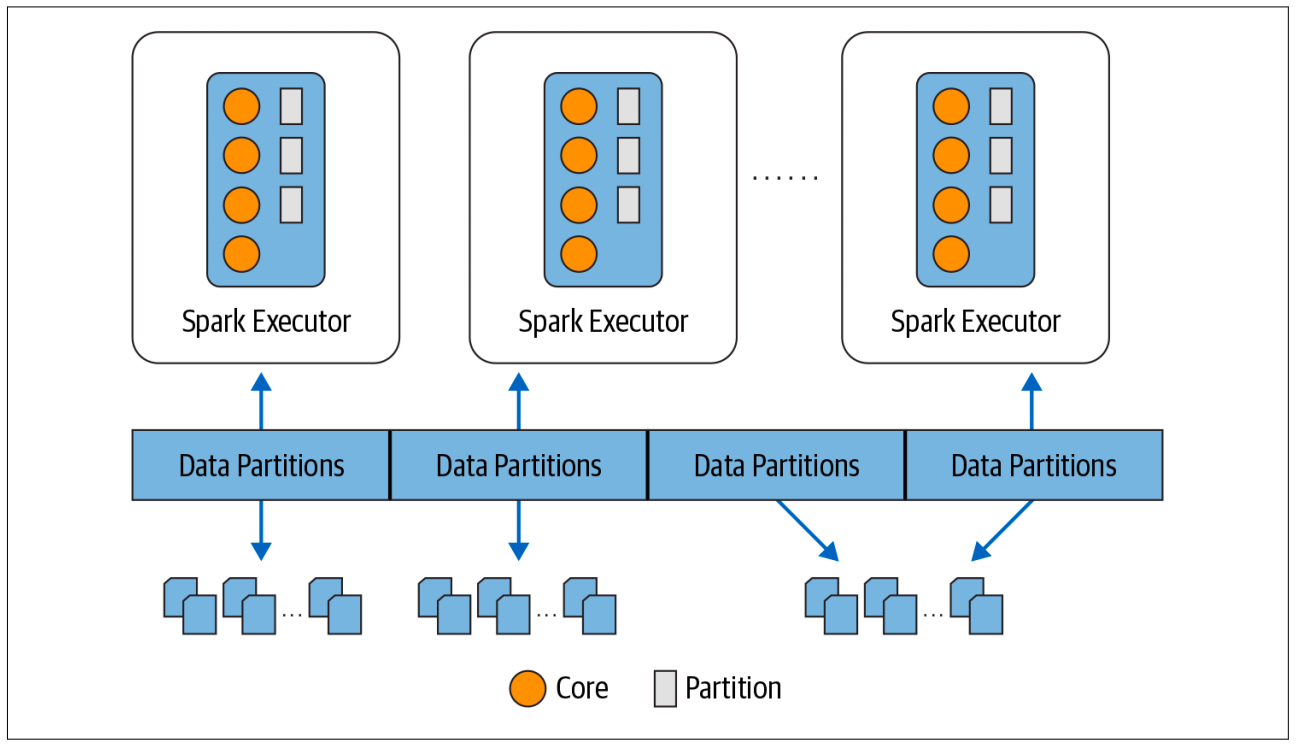
Partitions¶
Every RDD has a fixed number of partitions that determine the degree of parallelism to use when executing operations on the RDD.
Out of the box, Spark will infer what it thinks is a good degree of parallelism for RDDs, and this is sufficient for many use cases.
This code will create a DataFrame of 10,000 integers distributed over eight partitions in memory:
rdd = sc.range(0, 10000, 1, 8)
print(rdd.getNumPartitions())
8
Partitions¶
glom() Return an RDD created by coalescing all elements within each partition into a list.
numPartitions = 2
rdd = sc.parallelize([i for i in range(10)], numPartitions)
print(f"Number of partitions: {rdd.getNumPartitions()}")
print(f"Partitions: {rdd.glom().collect()}")
Number of partitions: 2 Partitions: [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
numPartitions = 10
rdd = sc.parallelize([i for i in range(10)], numPartitions)
print(f"Number of partitions: {rdd.getNumPartitions()}")
print(f"Number of partitions: {rdd.glom().collect()}")
Number of partitions: 10 Number of partitions: [[0], [1], [2], [3], [4], [5], [6], [7], [8], [9]]
Partitions¶
What happens when there are more partitions than elements in the RDD?
numPartitions = 20
rdd = sc.parallelize([i for i in range(10)], numPartitions)
print(f"Number of partitions: {rdd.getNumPartitions()}")
print(f"Number of partitions: {rdd.glom().collect()}")
Number of partitions: 20 Number of partitions: [[], [0], [], [1], [], [2], [], [3], [], [4], [], [5], [], [6], [], [7], [], [8], [], [9]]
You can see that Spark created the requested number of partitions but most of them are empty.
Partitions¶
If there is too much parallelism, small overheads associated with each partition can add up and become significant.
%timeit sc.parallelize([i for i in range(1000)], 1).map(lambda x: x ** 2).count()
41.1 ms ± 14.2 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit sc.parallelize([i for i in range(1000)], 1000).map(lambda x: x ** 2).count()
3.1 s ± 450 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In general, more numerous partitions allow work to be distributed among more workers, but fewer partitions allow work to be done in larger chunks (and often quicker).
Repartition¶
To change the number of partition in an rdd use .repartition() or .coalesce().
The repartition algorithm does a full shuffle and creates new partitions with data that's distributed evenly (more on that later).
rdd = sc.parallelize([i for i in range(10)], 10)
rdd = rdd.repartition(5)
rdd.getNumPartitions()
5
The .coalesce() can only reduce the number of partition in the RDD and it therefore avoids a full shuffle.
rdd = sc.parallelize([i for i in range(10)], 10)
rdd = rdd.coalesce(5)
rdd.getNumPartitions()
5
Cache and Persist¶
.cache() will store as many of the partitions read in memory across Spark executors as memory allows. While a DataFrame may be fractionally cached, partitions cannot be fractionally cached (e.g., if you have 8 partitions but only 4.5 partitions can fit in memory, only 4 will be cached). However, if not all your partitions are cached, when you want to access the data again, the partitions that are not cached will have to be recomputed, slowing down your Spark job.
The .persist() method does the same but allows for more fine graned control over how the data is cached.
Cache and Persist¶
import time
rdd = (
sc.parallelize([i for i in range(10000000)], 1)
.map(lambda x: x ** 2)
)
rdd.cache()
start = time.perf_counter()
rdd.count()
print("Count took", time.perf_counter() - start, "Seconds")
start = time.perf_counter()
rdd.count()
print("Count took", time.perf_counter() - start, "Seconds")
Count took 4.656902791999997 Seconds Count took 0.6131562499999959 Seconds
The first count() materializes the cache, whereas the second one accesses the cache, resulting in faster access time for this dataset.
When to Cache and Persist¶
Common use cases for caching are scenarios where you will want to access a large data set repeatedly for queries or transformations. Some examples include:
- DataFrames commonly used during iterative machine learning training
- DataFrames accessed commonly for doing frequent transformations during ETL or building data pipelines
When not to cache. Not all use cases dictate the need to cache. Some scenarios that may not warrant cach‐ ing your DataFrames include:
- DataFrames that are too big to fit in memory
- An inexpensive transformation on a DataFrame not requiring frequent use, regardless of size.